%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Attention Mechanism
Flexheadfa
FlexHeadFA is an improved model based on FlashAttention, focusing on providing a fast and memory-efficient accurate attention mechanism. It supports flexible head dimension configuration, significantly enhancing the performance and efficiency of large language models. Key advantages include efficient GPU resource utilization, support for various head dimension configurations, and compatibility with FlashAttention-2 and FlashAttention-3. It is suitable for deep learning scenarios requiring efficient computation and memory optimization, especially excelling in handling long sequences.
Model Training and Deployment
53.0K
Moba
MoBA (Mixture of Block Attention) is an innovative attention mechanism specifically designed for large language models dealing with long text contexts. It achieves efficient long sequence processing by dividing the context into blocks and allowing each query token to learn to focus on the most relevant blocks. MoBA's main advantage is its ability to seamlessly switch between full attention and sparse attention, ensuring performance while improving computational efficiency. This technology is suitable for tasks that require processing long texts, such as document analysis and code generation, and can significantly reduce computational costs while maintaining high model performance. The open-source implementation of MoBA provides researchers and developers with a powerful tool, driving the application of large language models in long text processing.
Model Training and Deployment
54.6K
Star Attention
Star-Attention is a novel block-sparse attention mechanism proposed by NVIDIA aimed at improving the inference efficiency of large language models (LLMs) based on Transformers for long sequences. This technology significantly boosts inference speed through a two-stage operation while maintaining an accuracy rate of 95-100%. It is compatible with most Transformer-based LLMs, allowing for direct use without additional training or fine-tuning, and can be combined with other optimization methods such as Flash Attention and KV cache compression techniques to further enhance performance.
Model Training and Deployment
52.2K

Motionclr
MotionCLR is an attention mechanism-based motion diffusion model focused on generating and editing human actions. It achieves fine control and editing of motion sequences through self-attention and cross-attention mechanisms, simulating interactions both within and between modalities. The main advantages of this model include the ability to edit without training, good interpretability, and the capability to implement various motion editing methods by manipulating the attention maps, such as emphasizing or diminishing actions, in-place action replacement, and example-based action generation. The research background of MotionCLR is to address the shortcomings of previous motion diffusion models in fine-grained editing capabilities, enhancing the flexibility and precision of motion editing through clear text-action correspondence.
AI Model
53.0K
Flashattention
FlashAttention is an open-source attention mechanism library designed specifically for Transformer models in deep learning to enhance computational efficiency and memory usage. It optimizes attention calculation using IO-aware methods, reducing memory consumption while maintaining precise computational results. FlashAttention-2 further improves parallelism and workload distribution, while FlashAttention-3 is optimized for Hopper GPUs, supporting FP16 and BF16 data types.
AI Model
53.0K
Fresh Picks
Mamba 2
Mamba-2, developed by Goomba AI Lab, is a novel sequential model designed to enhance the efficiency and performance of sequential models within the machine learning community. It utilizes the Structural State Space Dual (SSD) model, combining the advantages of state space models (SSM) and attention mechanisms, providing a more efficient training process and larger state dimensionality. Mamba-2's design allows for matrix multiplication during training, thereby improving hardware efficiency. Furthermore, Mamba-2 demonstrates strong performance in tasks like multi-query associative memory (MQAR), showcasing its potential in handling complex sequential processing tasks.
AI Model
57.4K
Era3d
Era3D is an open-source high-resolution multi-view diffusion model that generates high-quality images through an efficient row attention mechanism. The model can generate multi-view color and normal images and supports customizable parameters to achieve optimal results. Era3D is significant in the field of image generation because it offers a novel approach to generating realistic three-dimensional images.
AI image generation
74.5K
Gemma 2B 10M
The Gemma 2B - 10M Context is a large-scale language model that, through innovative attention mechanism optimization, can process sequences up to 10M long with memory usage less than 32GB. The model employs recurrent localized attention technology, inspired by the Transformer-XL paper, making it a powerful tool for handling large-scale language tasks.
AI Model
59.9K

Mixture Of Attention (MoA)
Mixture-of-Attention (MoA) is a novel architecture for personalized text-to-image diffusion models. It leverages two attention pathways - a personalization branch and a non-personalization prior branch - to allocate the generation workload. MoA is designed to retain the prior knowledge of the original model while minimally interfering with the generation process through the personalization branch, which learns to embed themes into the layout and context generated by the prior branch. MoA employs a novel routing mechanism to manage the distribution of each pixel across these branches at each layer, optimizing the blending of personalized and general content creation. After training, MoA can create high-quality, personalized images that showcase the composition and interaction of multiple themes, with the same diversity as images generated by the original model. MoA enhances the model's ability to distinguish between pre-existing capabilities and newly introduced personalized interventions, providing previously unattainable decoupled theme context control.
AI image generation
66.8K
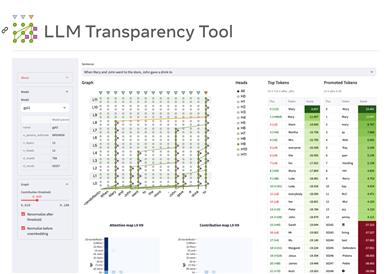
LLM Transparency Tool
The LLM Transparency Tool (LLM-TT) is an open-source, interactive toolkit for analyzing the inner workings of Transformer-based language models. It allows users to select a model, add prompts, and run inference, visualizing the model's attention flow and information transfer paths. This tool aims to increase model transparency, helping researchers and developers better understand and improve language models.
AI Model
64.9K
Featured AI Tools
English Picks

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
50.0K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
45.5K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
43.3K
Chinese Picks

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
43.6K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
45.8K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
43.3K
English Picks

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
Chinese Picks

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M